Drill down questions: what causes the high latency for single block reads during backup? Why do the sequential IO of the backup causes random reads to slow down? Are disks saturating? Is it an Oracle issue or more a storage issue? Finally, what can be done about it?
Oracle event histogram: Oracle instrumentation of wait events provides additional information in terms of histograms. Wait duration is divided in intervals and for each interval we can see how many wait events have happened. Historical data is collected and visible in AWR.
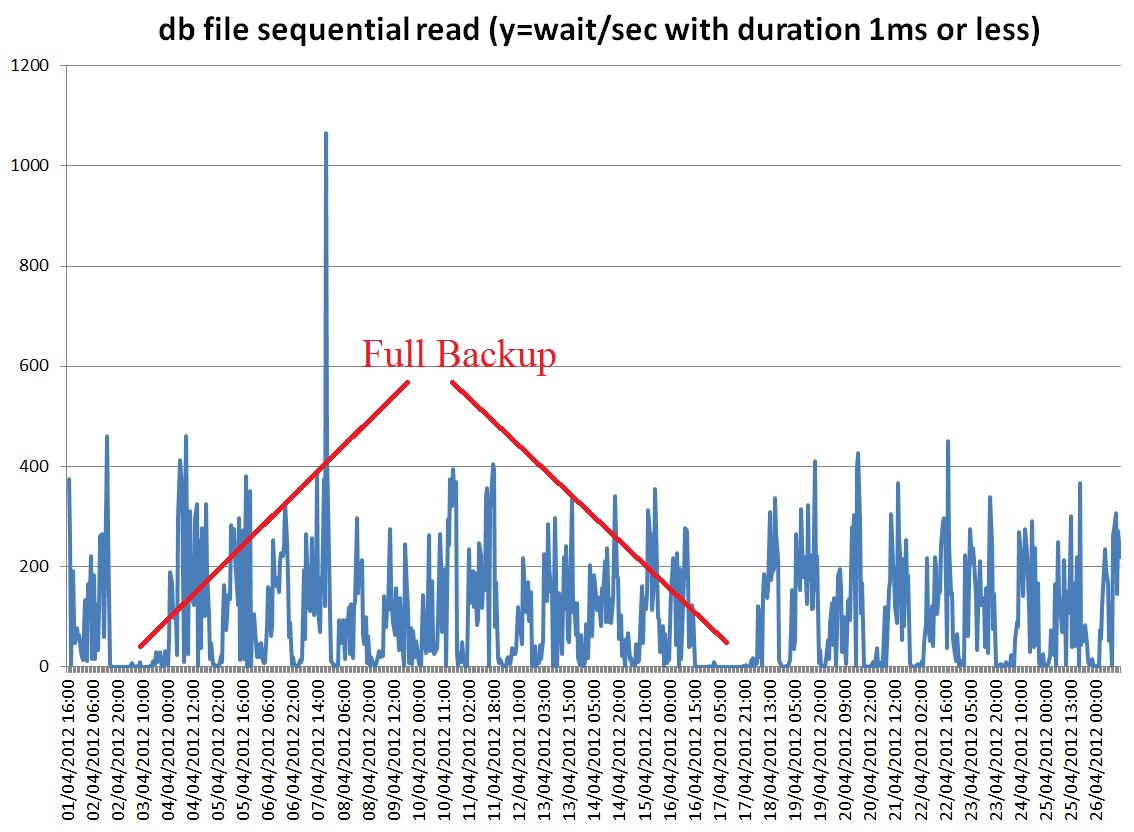
AWR data: Graph of data from DBA_HIST_EVENT_HISTOGRAM for the event db file sequential read are reported here below. In particular we can see that read of 1ms or less, that is reads served by the SSD cache of the storage, go to zero during the time backups are taken. Moreover wait of long duration (between 64 and 128 ms, which is a very long time for single block reads) show a peak at the same time.

Graph1: "Number of single block reads of 64 ms or more (that is very slow)" plotted as function of time. Large peaks are seen in correspondence of full backups (every 2 weeks), smaller peaks during daily backups.
First conclusions and future work: IO becomes slow because backups effectively seem to flush the SSD cache. Also Very long response times are seen from single block IO. There is work to do on the storage side!
What about actions on the DB? Moving backup to the (active) Data Guard, can be of help, as it would effectively remove the workload source of contention.
Techniques and references: To analyze AWR data I have built a set of custom queries against dba_hist_* views and used them inside the excellent Perfsheet by Tanel Poder.
Moreover I'd like to reference James Morle's blog.
This is the text of the query used, among others, to generate the graph above:
--event histogram with wait_count rate and time
select cast(sn.begin_interval_time as date) beg_time,
eh.dbid,
sn.instance_number,
eh.event_name,
eh.wait_time_milli,
eh.wait_count,
eh.wait_count - lag(eh.wait_count) over (partition by eh.dbid,eh.instance_number,eh.event_id,eh.wait_time_milli order by sn.snap_id nulls first) Delta_wait_count,
extract(hour from END_INTERVAL_TIME-begin_interval_time)*3600
+ extract(minute from END_INTERVAL_TIME-begin_interval_time)* 60
+ extract(second from END_INTERVAL_TIME-begin_interval_time) DeltaT_sec,
round((eh.wait_count - lag(eh.wait_count) over (partition by eh.dbid,eh.instance_number,eh.event_id,eh.wait_time_milli order by sn.snap_id nulls first)) /
(extract(hour from END_INTERVAL_TIME-begin_interval_time)*3600
+ extract(minute from END_INTERVAL_TIME-begin_interval_time)* 60
+ extract(second from END_INTERVAL_TIME-begin_interval_time)),2 ) Rate_wait_count_per_bin
from dba_hist_event_histogram eh,
dba_hist_snapshot sn
where
%FILTER%
and sn.snap_id = eh.snap_id
and sn.dbid = eh.dbid
and sn.instance_number = eh.instance_number
and sn.begin_interval_time between %FROM_DATE% and %TO_DATE%
No comments:
Post a Comment